ブログ
AIエージェントの法的留意点 AIエージェントと開発② ―AIエージェントの開発契約とリスク管理―
2025.04.14
SHARE![]()
![]()
![]()
はじめに
前回のブログでは、経済産業省が公表した「AIの利用・開発に関する契約チェックリスト」(以下「本チェックリスト」といいます。)[i]を参考にしながら、AIエージェント開発に関する基本的な法的留意点を概観しました。
本記事では、具体的なAIエージェントの開発を念頭に置いて、実務上の法的なリスクを取り上げ、それに対する契約上の対応策として、特にAIエージェント固有のガードレールの設定や責任分配、複数の基盤モデル利用時の留意点について説明します。
本記事の要点―AIエージェントの開発契約とリスク管理のポイント
- サービスの全体像の把握
ユーザがAIエージェントをどのように利用するのか、ベンダがどのようなサービスを提供するのかを明確にします。 - インプットとアウトプットの整理
提供される情報(インプット)と生成される成果物(アウトプット)を特定し、それぞれの使用条件や権利帰属を明確にします。 - ガードレールの設定
AIエージェントが誤情報や差別的な発言をしないよう、適切な制限(ガードレール)を設けます。 - リスク分配の明確化
AIエージェントの出力に関するリスクが現実化した場合の責任分配を契約上で明確にすることを検討します。 - 複数の基盤モデルの利用時の留意点
異なるAIモデルを組み合わせて使用する場合、それぞれの利用規約や成果物の権利帰属に注意します。
開発契約の仮想事例
AIエージェントの開発は、何らかの既存の基盤モデルを用いて、新たなシステムを開発することが多いと考えられます。本チェックリストでも、特にベンダがユーザに対してユーザ向けに改良・調整したAIサービスを提供する契約(カスタマイズ型の契約)では、第三者が提供する汎用的AIサービスを組み込んでいるケースが想定されています。[ii]
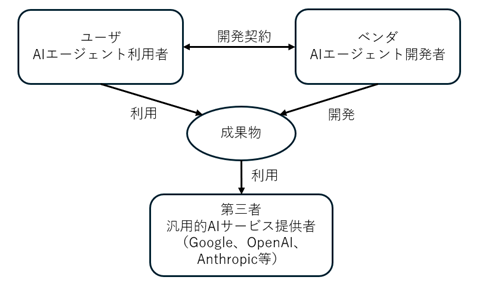
本記事では、ベンダが、第三者が提供する汎用的AIサービスを用いて、ユーザの顧客に対し、高度なFAQ対応やチャットボットなど自動で対応するAIエージェントを開発する場合(以下「本事例」といいます。)を想定して、開発契約について検討を行います。
AIの利用・開発において共通する留意事項
契約の検討に当たっては、まず提供しようとするサービス及び開発の全体像を把握することが出発点となります。具体的には、サービスの完成形を想定したうえで、ユーザが自社サービスの一環としてAIエージェントを利用するのか、又はベンダがAIエージェントをサービス(SaaS)としてユーザに提供するのか、といったサービスの構造を整理し、開発のためにどのような情報をインプットして、どのようなアウトプットを想定して開発を行うのかという点などを検討し、サービス及び開発の全体像を理解する必要があります。
その上で、開発におけるインプットとアウトプットの流れに即して、個別に検討していく必要があります。まず、開発において、把握した全体像に基づき、インプットとしてどのような情報を提供するのか/されるのかを検討して特定し、具体的に特定した情報について、提供範囲や使用条件、第三者提供の可否といった点を確認していきます。また、アウトプットについても、把握した全体像に基づき、どのようなアウトプットを想定して開発を行うのかを検討して特定し、アウトプットの具体的な内容に応じて、成果物を完成させる義務を規定するのか、業務の遂行義務だけを規定するのか(報告書などの業務内容の報告を成果物とするのか)などを検討し、利用条件、第三者提供、権利帰属といった要素も整理していきます。
本チェックリストは、このような整理に有用です。以下の表1に示すとおり、インプットとアウトプットそれぞれの側面から契約条件を分析するための枠組みが示されています。[iii]
(表1)
|
検討事項 |
インプットにおける検討 |
アウトプットにおける検討 |
|
特定 |
インプットする情報として具体的に何を想定するかを検討 |
アウトプットとして具体的に何を想定するかを検討 |
|
提供 |
インプットの提供範囲、提供義務等を検討 |
アウトプットの完成義務、提供義務等を検討 |
|
使用・利用 |
インプットの使用条件、目的、範囲等を検討 |
アウトプットの使用条件、目的、範囲等を検討 |
|
外部提供 |
インプットの第三者への提供可否、提供可能な場合の条件等を検討 |
アウトプットの第三者への提供可否、提供可能な場合の条件等を検討 |
|
権利帰属 |
インプットの権利帰属を検討 |
アウトプットの権利帰属を検討 |
このような分析の流れにおいて、法的に問題になりやすい事項としては、個人情報や秘密情報を含むインプットの扱い、アウトプットの権利帰属の扱いなどが考えられますので、以下、これらの事項について、概観します。
まず、インプットにおいては、インプットするデータの性質が問題になります。単なるデータそれ自体は、所有権等の物権の対象にはならず、知的財産権等として保護されることもないため、法定の権利が発生するものではありません。そのため、契約上で利用条件を定めない限りは、データを提供する側だけでなく、提供される側も、自由にデータを利用することができます。そこで、契約上、どのようにデータの利用条件を定めるかが問題になります。
次に、インプットにおける個人情報の取扱いについては、個人情報保護法上の第三者提供規制(27条)の対象になるか否かの判断が求められます。もしインプットとして提供する個人データについて、委託として整理できれば、第三者提供規制の問題はなくなります(法27条5項1号。なお、越境移転規制(法28条)は別ですし、委託先の監督(法25条)等は必要です。)。このとき、インプットした個人データについて、ベンダが保有する個人データと照合したり、ベンダが他の開発に流用する場合には、委託の範囲を超える可能性があり、委託として整理できない場合があることに注意が必要です。委託として整理を行う場合には、インプットの使用条件や目的等を明確に定める必要があります。
また、インプットにユーザの営業秘密やユーザが第三者との間で秘密保持義務を負う情報等の秘密情報が含まれる場合に、ベンダが当該情報をモデルの改良に用いるなど他の開発に流用すると、営業秘密としての保護が失われたり、秘密保持義務に違反したりする可能性があります。そのため、ベンダとの間で、秘密保持の条項を入れたり、インプットの使用条件や目的等を明確に定める必要があります。
さらに、アウトプットについても、そもそもユーザがアウトプットの内容としてどの程度の内容・水準のものを求めるかが重要な論点となることも少なくありませんが[iv]、具体的なアウトプットが想定される場合には、知的財産権の帰属及び使用範囲を明確にしておくことが必要です。
AIエージェントの開発における留意事項
(1)アウトプットの特定
AIエージェントの開発は、基盤モデルを用いた新しいシステムを開発することになり、基盤モデルの内部的な計算や処理過程が不透明であるため、事前に具体的な成果物を特定することが困難な場合が想定されます。
このことは、学習済みモデルを開発する場合に、事前に性能保証をすることは困難であり、事後的な検証も困難であることと共通しています。[v]
このような場合には、①アセスメント段階、②PoC段階、③開発段階、④追加学習段階の4段階による探索的段階型の開発方式が提唱されています。[vi]
AIエージェントの開発でも、このような開発方式を採り、それぞれの段階に応じて、アウトプットを特定し、契約条件を整理していくことが考えられます。
(2)ガードレールの検討
AIエージェントは、特定の目標を達成するために、一定のタスクを順次実行するため、人間の直接的な判断を経ることなく、独自の判断で動く可能性があります。本事例のような場合、顧客に対して自動で対応が行われるため、開発後のアウトプットの利用段階で、顧客に対し、誤情報を提供したり、差別的な言動を行ったりするリスクが考えられます。
このようなリスクを軽減するためには、「ガードレール」として、問題のあるアウトプットが自動で行われることのないような制限について検討する必要があります。[vii]本チェックリストでも、基盤モデルを含むAIシステムを開発する場合には、出力等の不確実性を十分に考慮したシステム設計・開発が求められる可能性が指摘されています。[viii]
このようなガードレールについては、技術的な内容を含むため、一般的には、契約書本文ではなく、仕様書の中で定義されることが多いと考えられます。
(3)リスク分配の検討
例えば、本事例で、AIエージェントが顧客に対して差別的な言動を行う場合など、リスクが現実化することも想定されます。
このような場合、顧客に直接サービスを提供するのはユーザであるため、ユーザが顧客に対して法的責任を負うかが一次的に問題になります。ユーザは、AIエージェントを現状有姿で提供し、結果の保証等はしないことが多いと考えられるものの、このような差別的な言動については、その内容次第では、少なくとも不法行為責任(民法709条)を負う可能性があります。
他方で、ベンダは、顧客との関係では、契約責任は負いません。また、ユーザとの関係でも、契約不適合(民法第562条)がない限り、原則として責任を負わないと解されます。さらに、製造物責任法は、有体物を前提とするため(同法第2条)、ソフトウェアであるAIエージェントには適用されません。ただし、不法行為責任は負う可能性があります。
このように、ユーザとベンダの両者に法的責任が生じる可能性があることからすれば、事前に、リスクをどのように分配するかを明確化しておくことは検討に値します。ただし、本チェックリストで指摘されているように、AIモデルの出力等の不確実性について、一つの契約によってリスク分配を図ることが適切か、特に運用に関する契約を締結することが決まっている場合には、その後の契約で段階的に調整をしていく方が良い可能性もあり[ix]、具体的な開発の全体像に応じて検討する必要があります。
複数の基盤モデルを利用する場合の留意点
本チェックリストでは、第三者が提供する汎用的AIサービスを組み込んでいるシステムを開発するケースにおいて、第三者がベンダを介して提供するAIサービスに関する利用規約等についても、確認することが考えられると指摘されています。[x]AIエージェントにおいては、第三者の提供する基盤モデルについて、単一の基盤モデルだけではなく、複数の基盤モデルを利用する場合があり、確認内容が複雑化することが予想されます。
例えば、以下のようなことが考えられます。
- 各モデルの利用規約の確認と調整
モデル提供者ごとに、利用可能なインプット・アウトプットの条件が異なる場合、契約条件が抵触しないように調整する必要があります。一方が生成物の商用利用を許可しない場合、エージェント全体の提供形態が制限される可能性があります。 - アウトプットの権利帰属の明確化
各モデルの利用規約に「成果物に関する知的財産権は当社に帰属する」などの定めがある場合、ユーザに提供するエージェント全体の法的整理が複雑化します。 - 責任分配の明確化
エージェントに不適切な出力が含まれていた場合、どのモデルの影響によるものか、因果関係を特定することは困難ですが、モデル提供者とは個別に責任分配の合意をすることは困難な場合が多いと考えられ、ユーザとベンダの間で、責任分配を明確化しておく必要性は高くなります。
まとめ
本記事では、AIエージェントの開発契約を検討するに当たり、契約の出発点となるサービスの全体像の把握から、インプット・アウトプットの整理、更にはAIエージェントのリスクであるガードレールや責任分配の問題、そして複数の基盤モデルを利用する際の留意点まで、契約実務において重要となる論点を幅広く取り上げました。
AIエージェントは、従来のシステム開発と比較して、その出力の不確実性や自律性の高さにより、契約上の検討事項も複雑化しています。したがって、本チェックリストのような整理手法を活用しつつ、段階的かつ柔軟に契約条件を設計していく姿勢が求められます。
AIエージェントの導入が進んでいく中で、今後も新たな論点や実務的課題が現れてくることが予想されます。次回以降のブログでは、開発契約を離れて、AIエージェントに対するインプット、AIエージェントによるアウトプットの問題等について、検討を深めていきたいと思います。
以上
[i] 経済産業省「AIの利用・開発に関する契約チェックリスト」(2025年2月)(https://www.meti.go.jp/press/2024/02/20250218003/20250218003.html)
[ii] 前掲注i)25頁
[iii] 前掲注i)10頁
[iv] 前掲注i)31頁
[v] 前掲注i)32頁
[vi] 経済産業省「AI・データの利用に関する契約ガイドライン AI編」(2018年6月)(https://www.meti.go.jp/policy/mono_info_service/connected_industries/sharing_and_utilization/20180615001-3.pdf)43頁
[vii] 日経ビジネス2025年1月27日号21頁
[viii] 前掲注i)32頁
[ix] 前掲注i)32頁
[x] 前掲注i)25頁
Member
PROFILE

SHARE![]()
![]()
![]()